Cosmology & General Relativity
Statistical Field Theory
Lensing as a path integral over the Sachs optical scalars
Zheng Zhang Jodrell Bank Centre for Astrophysics, The University of Manchester
11 June 2026 · Old Prison of Aegina, Greece
based on the following work
(in prep.) :
Statistical Field Theory for Weak Gravitational Lensing Z. Zhang, P. Bull, C. Clarkson, A. Nicola
SFT-WICK: Automating Wick contractions & Feynman diagrams for stochastic field theories Z. Zhang
CANOES: Cosmological ANgular Observables and Estimator Suite Z. Zhang, P. Bull, A. Nicola
background κ-map: Gevolution (ΛCDM N-body)
[Greet, then the one-sentence framing.] Good morning, and thank you. Here is the single sentence the whole talk defends: the textbook projection formula that every weak-lensing survey uses is not a separate model, it is the leading term of one systematic field-theory expansion, and the very next term carries the matter bispectrum, a three-point quantity, into the two-point lensing signal, where nobody is currently looking for it. The background is a real relativistic N-body convergence field. This builds on three papers in preparation: the theory paper with Phil Bull, Chris Clarkson and Andrina Nicola, and two companion codes, sft-wick for the diagrammatics and canoes for the driving-field statistics.
The observable
A decade of weak lensing is arriving
Surveys are mapping billions of galaxy shapes:
Rubin / LSST · ~20 billion galaxies imaged (~2 billion WL shapes) Euclid · 1.5 billion shapes, deep IR Roman · high-resolution space shear
Cosmic shear: the tiny, spatially-coherent stretching of galaxy shapes by all the intervening mass — a spin-2 field on the sky. The Stage-IV precision jump puts the modelling under real pressure.
Galaxy ellipses tangentially stretched around unseen mass — coherent shear "whiskers".
[Gesture at the whisker field.] We are at the start of a remarkable decade. Rubin's LSST will image about twenty billion galaxies, a few billion of them with shapes precise enough for weak lensing; Euclid around one and a half billion shapes with deep infrared; Roman adds high-resolution shear from space. For the relativists: the observable is cosmic shear. Every galaxy image is slightly distorted by the gravitational field of all the matter between it and us. The distortion is tiny, a percent-level stretch, but spatially coherent, and it is a spin-2 field: nearby galaxies are sheared in nearly the same direction, the whiskers you see here, stretched tangentially around concentrations of unseen mass. Weak lensing is the premier Stage-IV probe because it responds to all the mass; the precision is about to jump by an order of magnitude, which puts the modelling under real pressure.
The standard picture
Lensing is treated as a projection
Sum the matter density along the line of sight, weighted by a geometric kernel.
\[ \kappa(\hat{\mathbf n}) = \int_0^{\chi_s}\! d\chi\; W(\chi)\,\delta\!\big(\chi\hat{\mathbf n},\chi\big) \]
A clean, linear hierarchy follows:
\( \xi_\kappa \leftarrow P_{\rm m}(k) \qquad \zeta_\kappa \leftarrow B_{\rm m}(k_1,k_2,k_3) \)
The Born & Limber approximations: simple, fast, the workhorse behind every Stage-IV forecast.
[Point to the kappa equation.] Here is how the modelling is done today. The convergence in a direction is an integral of the matter density along the line of sight, weighted by a geometric kernel. It rests on two approximations. Born: integrate along the unperturbed straight ray, ignoring how the ray bends. Limber: collapse radial correlations to a single shell. For relativists, this is the photon treated as a passive accumulator along a fixed path. What it gives you is a clean linear hierarchy: the two-point function of the convergence inherits the matter power spectrum, the three-point inherits the bispectrum, one to one. Simple, fast, the workhorse behind every forecast. The question is how much weight that approximation can bear.
Motivation of this work
But the projection is an approximation
Its known corrections are each bolted on separately , in their own formalisms:
post-Born / lens–lens coupling
beyond-Limber radial mixing
higher-order corrections of the matter field
What does the projection throw away ,
Ray-tracing combines them — at the price of expensive runs, sample variance, and no clean answer to which mechanism dominates a residual.
[Let the central question sit.] It is an approximation, and we know how it fails. Post-Born lensing, where the ray bends and later lenses couple to earlier ones. Beyond-Limber radial mixing. And the higher-order corrections of the matter field itself. The trouble is not that we cannot compute these; it is that each lives in its own formalism, bolted on separately, and they do not naturally compose. To get all of them at once you run a ray-tracing simulation: it works, but it is expensive, carries sample variance, and when you see a residual it gives no clean answer to which mechanism produced it. So the central question: what, exactly, does the projection throw away, and when does it matter? To answer that cleanly, I want to go back to the geometry.
Part 1 · Back to the geometry
A photon bundle focuses and shears
\[ \dot\theta = -\theta^2-\sigma_+^2-\sigma_\times^2+\textcolor{#f5b942}{\Phi_{00}} \qquad \dot\sigma_{+,\times} = -2\,\theta\,\sigma_{+,\times}+\textcolor{#4cc9f0}{\mathcal{W}_{1,2}} \]
\(\Phi_{00}=-4\pi G\,T_{\mu\nu}k^\mu k^\nu\) — Ricci, matter density. ·
\(\Psi_0=-C_{\alpha\beta\gamma\delta}k^\alpha Z^\beta k^\gamma Z^\delta\) — Weyl, tides.
Standard lensing merges these into one \(\kappa\); we keep them separate.
[The spine. Slow down. Point to the two colour-coded sources.] Forget the projection and follow an actual bundle of light rays through curved spacetime. In GR this is the Sachs picture, governed by these optical-scalar equations. A bundle does two things: it changes size, isotropic focusing, the expansion theta; and it changes shape at fixed area, a squeezing, the shear sigma. The key point the projection erases: these are driven by two physically distinct pieces of curvature. Focusing, in amber, is sourced by Ricci curvature, which by Einstein's equations is the local matter density. Shearing, in cyan, is sourced by Weyl curvature, the tidal part, from matter off to the side. The right panel is the dictionary: which source drives which rate, and with what parity. Standard lensing merges them into one kappa; we keep them separate. Hold on to these two colours; they run through the whole talk.
Part 1 · Reframing
The spacetime is a random field
One realization of the field chain the bundle integrates through: \(\delta \to \Phi \to \Phi_{00},\,|\Psi_0|\).
Structure formation makes the curvature a draw from an ensemble : the Sachs sources \(\Phi_{00},\Psi_0\) become random fields , so the optical scalars are not a fixed integral but a stochastic dynamical system .
[Let the field chain sweep for a few seconds.] Here is the thing the projection hides. The curvature the bundle falls through is not a fixed function; it is one realization of structure in our Universe. Structure formation makes the Sachs sources, Ricci and Weyl, random fields, built from the matter density through the gravitational potential. So the optical scalars are not an integral to evaluate once; they are a stochastic dynamical system, differential equations driven by noise. And once you say "stochastic dynamical system driven by random fields," you have named a problem statistical field theory was built to solve. That is the whole move of the talk.
Part 1 · Reframing
Null-geodesic dynamics as a stochastic field theory
A distribution over the driving fields induces a functional probability over trajectories . The Sachs system is purely nonlinear, with no linear term to expand around, so first expand around the mean field : the fluctuation \(X = \vec X - X^{\rm(sa)}\) about the background saddle obeys
\[ \dot X_a = A_{ab}\,X_b + F_{abc}\,X_b\,X_c + \Delta S_a \]
A genuine linear drift appears — on FLRW just the background focusing, \(A_{ab}=-2\,\delta_{ab}\,\theta^{\rm(sa)}\), \(\theta^{\rm(sa)}=\dot{\bar D}/\bar D\). For each driving realization the trajectory is fixed, so a functional \(\delta\) pins it:
\[ P[X\,|\,\Delta S]=\prod_a \delta\!\big(\dot X_a - A_{ab}X_b - F_{abc}X_bX_c - \Delta S_a\big) \]
Martin–Siggia–Rose writes the probability of \(X\) as a path integral over \(X\) and a response field \(\tilde X\):
\[ P[X]\;\propto\!\int\!\mathcal{D}\tilde X\; e^{-S} \]
\[ S=\underbrace{\,i\!\int\!\tilde X_a(\dot X_a-A_{ab}X_b)}_{\text{linear}}-\,i\!\int\! F_{abc}\tilde X_a X_b X_c-W[i\tilde X] \]
Marginalising over the driving-field statistics \(P[\Delta S]\) collapses the source integral into its cumulant generating functional \(W\):
\[ W[i\tilde X]=\sum_{n\ge2}\frac{i^n}{n!}\int \kappa^{(n)}_{a_1\cdots a_n}\,\tilde X_{a_1}\!\cdots\tilde X_{a_n} \]
\(\kappa^{(n)}=\langle\Delta S_{a_1}\!\cdots\Delta S_{a_n}\rangle_c\): the connected driving-field cumulants — the only cosmological input. (\(F\): nonlinear vertex.)
SFT‑WICK — Automating Wick contractions & Feynman diagrams for stochastic field theories · Z. Zhang (in prep)
[Don't derive; point and move.] How do we compute with this? A probability over the driving-field realizations induces a functional probability over the trajectories. One wrinkle first: the Sachs system is purely nonlinear, with no linear term to expand around, so we make the standard field-theory move and expand around the mean field, subtracting the background saddle trajectory and working with the fluctuation X about the background saddle. That produces a genuine linear drift A, which on the FLRW background is just minus-two-theta, the background focusing rate, the derivative of the angular-diameter distance. Now Martin, Siggia and Rose write the probability of X, exactly, as a path integral over X and a response field X-tilde, weighted by e-to-the-minus-S. The action has a linear drift A, the nonlinear F vertex, and W. W is the object that matters here: marginalising over the driving-field realizations collapses the source integral into the cumulant generating functional of the driving field, so all the cosmological statistics, the connected cumulants of Ricci and Weyl, are packaged into W. Probability of the fields has become probability of the trajectories; the free propagators of this theory come on the next slide.
Part 1 · Reframing
Lensing observables are moments of that path integral
The lensing field whose moments we want (gevolution, ΛCDM).
Convergence \(\kappa\) and shear \(\gamma\) are line-of-sight integrals of the fluctuation Sachs scalars \(X=(\delta\theta,\delta\sigma_+,\delta\sigma_\times)\):
\[ \kappa=-\!\int_0^{\lambda}\!\delta\theta\,d\lambda',\quad \gamma_+\!\pm i\gamma_\times=-\!\int_0^{\lambda}\!(\delta\sigma_+\!\pm i\delta\sigma_\times)\,d\lambda' \]
So every statistic is a moment of \(X\), taken directly against the path integral:
\[ \langle X_{a_1}\!\cdots X_{a_n}\rangle=\!\int\!\mathcal{D}X\,\mathcal{D}\tilde X\;X_{a_1}\!\cdots X_{a_n}\,e^{-S} \]
No projection step is assumed: the moment is of the full stochastic solution.
[Let the globe turn slowly.] What we measure are statistics of the convergence: its two-point function, its three-point function, and so on. In this language each one is simply a moment of the Sachs field, an expectation value taken directly against the path-integral weight e-to-the-minus-S. Crucially, no projection step is inserted: we take the moment of the full stochastic solution of the optical equations, not of a linearized line-of-sight integral. The globe is the field whose moments we are after. The rest of the talk is: how do you actually compute these integrals, and what do they tell you.
Part 2 · The engine
Split the action, then Wick-contract
Split the action into a Gaussian reference plus interactions:
\[ \begin{aligned} S &= S_{\rm ref}+S_{\rm int},\\[2pt] S_{\rm int} &= \underbrace{-\,i\!\int\!F_{abc}\tilde X_a X_bX_c}_{F\ \text{vertex}}-\underbrace{\textstyle\sum_{k\ge3}W^{(k)}[i\tilde X]}_{K\ \text{vertices}} \end{aligned} \]
\[ S_{\rm ref}=i\!\int\!\tilde X_a(\dot X_a-A_{ab}X_b)-W^{(2)}[i\tilde X] \]
Expand each moment about the reference; Wick's theorem factorises it into the two free propagators, \(C\) (solid) and \(R\) (dashed, causal):
\[ \langle O\rangle_S=\sum_{n}\frac{(-1)^n}{n!}\,\big\langle O\,S_{\rm int}^{\,n}\big\rangle_{\rm ref} \]
The reference theory has exactly two free 2-point functions (and \(\langle\tilde X\tilde X\rangle_{\rm ref}=0\)):
\[ \langle X_a X_b\rangle_{\rm ref}=\textcolor{#4cc9f0}{C_{ab}},\qquad \langle \tilde X_a X_b\rangle_{\rm ref}=-i\,\textcolor{#f5b942}{R_{ab}} \]
\[ \textcolor{#f5b942}{R_{ab}}=\delta_{ab}\,\delta(\hat n'{-}\hat n)\,\Theta(\lambda'{-}\lambda)\,e^{-2\int_\lambda^{\lambda'}\theta^{\rm(sa)}d\tau} \]
\[ \textcolor{#4cc9f0}{C}=\textcolor{#f5b942}{R}\,\kappa^{(2)}\,\textcolor{#f5b942}{R}\quad(\kappa^{(2)}\text{: driving 2-cumulant}) \]
The contractions are the Feynman diagrams (sft-wick convention).
[Name the ingredients, then reveal the diagrams.] Once it is a path integral, the calculation is mechanical. Split the action into a Gaussian reference part plus interactions. The reference action is the linear drift plus the driving two-cumulant; the interactions are two vertices, F, the local nonlinear self-coupling, and the K vertices, which inject the higher driving cumulants. Now expand the exponential of minus-S-int; for the two-point function at second order you keep S-int squared, and Wick's theorem factorises every term into the two free propagators of the reference theory. There are exactly two: C, the correlation propagator, the field auto-correlation, drawn solid; and R, the response propagator, drawn dashed and strictly causal, which on the background is just the focusing exponential. R carries the driving noise into C. [click] And here is the payoff: every Wick contraction of these propagators at the F and K vertices is literally a Feynman diagram. The combinatorics explode, so we automate the whole thing in the companion package, sft-wick.
Part 2 · Does it work?
On a toy model, the diagram sum converges to the truth
A 2-field stochastic system with a known answer:
\[ \dot\varphi_1=-\varphi_1+\varphi_2^2+\eta_1,\qquad \dot\varphi_2=-\varphi_2+\varphi_1\varphi_2+\eta_2 \]
Driving noise (bottom) imprints on the solution (top).
Markers: direct Monte-Carlo (\(10^5\) realizations). Curve: the diagram sum, order 0→2→4, climbing onto the truth.
[Persuasion slide. Let the animation run a full loop.] Before trusting this on lensing, we earn that trust on a toy system simple enough to brute-force: two coupled stochastic fields driven by coloured noise. The waterfall shows one realization: the driving noise at the bottom imprinting its texture on the solution fields at the top. Now the test: the markers are the exact answer from a hundred thousand direct Monte-Carlo realizations; the curve is the sft-wick diagram sum, added order by order. Watch it climb onto the truth, each order shrinking the residual by roughly a factor of sixteen. This validates the machine itself, separate from any physics input. Then we point it at the Sachs system.
Part 2 · Application to cosmological weak lensing
From the response propagator to the lensing efficiency kernel
Correlation propagator \(C\): the response folded twice around the driving 2-cumulant \(\kappa^{(2)}\):
\[ C_{ij}=\!\int_0^{\lambda_1}\!\!\!d\lambda'\!\int_0^{\lambda_2}\!\!\!d\lambda''\,\Big(\tfrac{\bar D(\lambda')}{\bar D(\lambda_1)}\Big)^{\!2}\kappa^{(2)}_{ij}\,\Big(\tfrac{\bar D(\lambda'')}{\bar D(\lambda_2)}\Big)^{\!2} \]
Projected onto convergence, the two responses fold into kernels — the textbook projection drops out:
\[ \xi_\kappa=\!\int_0^{\lambda_s}\!\!\!d\lambda'\!\int_0^{\lambda_s'}\!\!\!d\lambda''\,\textcolor{#f5b942}{K(\lambda',\lambda_s)}\,\textcolor{#f5b942}{K(\lambda'',\lambda_s')}\,\kappa^{(2)}_{11}(\gamma;\lambda',\lambda'') \]
Exact — no Limber, no projection assumed: \(K\) is the order-0 response.
On FLRW the response is causal, direction-local, a ratio of angular-diameter distances \(\bar D=a\chi\):
\[ R_{ij}=\delta_{ij}\,\delta(\hat{\mathbf n}-\hat{\mathbf n}')\Big(\tfrac{\bar D(\lambda)}{\bar D(\lambda')}\Big)^{2},\ \ \lambda<\lambda' \]
Its window has two equivalent forms — an affine-parameter integral and a closed comoving expression, the textbook lensing efficiency kernel :
\[ K=\bar D^2(\lambda)\!\!\int_\lambda^{\lambda_s}\!\!\tfrac{d\lambda_1}{\bar D^2(\lambda_1)}=a^2\,\tfrac{\chi(\chi_s-\chi)}{\chi_s} \]
The conventional weak-lensing window is the order-0 response — not an input, a consequence.
[The response IS the lensing kernel.] On the FLRW background the response propagator is causal, direction-local, and carries a ratio of squared angular-diameter distances, D-bar equals a-times-chi. The key point: change variables from the affine parameter to comoving distance and this propagator collapses, exactly, to the textbook weak-lensing efficiency kernel, chi times chi-s-minus-chi over chi-s, the window that peaks roughly half-way to the source. So the conventional lensing kernel is not an assumption we feed in; it is the order-zero response propagator of this field theory, derived. [click] And the correlation propagator is just this response folded twice around the driving two-cumulant; projecting it onto the convergence, the two responses fold into two copies of that same kernel, and out drops the textbook line-of-sight projection, exactly, with no Limber approximation. The standard weak-lensing two-point estimator is the order-zero diagram of this theory.
Part 2 · Application to cosmological weak lensing
Driving-field statistics, from one input \(P_\delta(k)\)
2-cumulant (Gaussian power). The Ricci (\(\Phi_{00}\)) and Weyl (\(\Psi_0\)) driving fields are screen-space derivatives of the light-cone potentials \(\Phi,\Psi\):
\[ \Phi_{00}=-\tfrac{E_0^2(1{+}z)^2}{a^2}\Big[\tfrac12\nabla_\perp^2(\Phi{+}\Psi)+\mathcal D^2\Phi+\cdots\Big] \]
\[ \Psi_0=-\tfrac{E_0^2(1{+}z)^2}{a^2}\,\hat s^i\hat s^j\,\partial_i\partial_j(\Phi{+}\Psi) \]
Per multipole each derivative is a single angular multiplier — the spin weight is explicit:
\[ \Phi_{00}:\ \frac{L^2}{\chi^2},\qquad \Psi_0:\ \frac{\sqrt{L^2(L^2{-}2)}}{\chi^2},\qquad L^2\equiv\ell(\ell{+}1) \]
Spin-0 trace (focusing) vs spin-2 \(\eth^2\) shear (\(\to 0\) for \(\ell<2\)); all from \(P_\delta(k)\).
3-cumulant \(\zeta\) (non-Gaussian). Tree-level matter bispectrum (\(\propto D^4\)),
\[ B_\delta=2\,F_2^{(s)}(\mathbf k_1,\mathbf k_2)\,P_\delta P_\delta+\text{cyc.} \]
projected to the modulus spin channels that survive the contraction,
\[ \zeta_B=\langle\Phi_{00}|\Psi_0|^2\rangle,\quad \zeta_D=\langle\Psi_0|\Psi_0|^2\rangle \]
Equal-shell (squeezed) limit, \(<\)0.5% error. Built by canoes .
[The physics input, words first.] All the cosmology enters through the driving-field cumulants, built from one input, the matter power spectrum. The two-cumulant is the matter power transferred to the Sachs sources by screen-space operators, a Laplacian for the Ricci focusing scalar and a spin-two operator for the Weyl shear scalar, then projected with the lensing-efficiency kernels exactly, with no Limber approximation across equal-redshift shells. The three-cumulant is the tree-level matter bispectrum, the standard F-two kernel, growing as the fourth power of the growth factor, projected onto the same fields. The subtlety that matters: only the modulus spin channels, Phi-zero-zero times mod-Psi-squared and Psi times mod-Psi-squared, survive the contraction; the un-conjugated combinations vanish at small angle. We compute all of this on the real light cone in the companion code, canoes.
Part 3 · The lensing 2PCF
Example: The convergence 2PCF, order by order
No single vertex feeds a connected 2-point function, so the leading correction is order 2 , in three groups — a preview of the insights:
O0
A unified view — the conventional kernel, \(\xi_\kappa=\int\!\!\int C_{11}\,d\lambda_1 d\lambda_2\)
FK
Statistical Hierarchy Mixing
[Set up the result slides.] Here is the lensing two-point function: contract the two external convergence legs through the correlation propagator and integrate along the two lines of sight. Now expand. At first order, no single vertex insertion can feed a connected two-point function, by the topology. So the leading correction is second order, and it falls into three groups, boxed here in the package's own diagram convention. O0, the free theory, is the conventional kernel. FF, with two F vertices, is nonlinear propagation. FK, one F and one K, takes the driving-field three-cumulant and feeds it through a single propagation gate into the two-point function. These are the entire leading expansion. The next slides are what they tell us.
Part 3 · Insight A
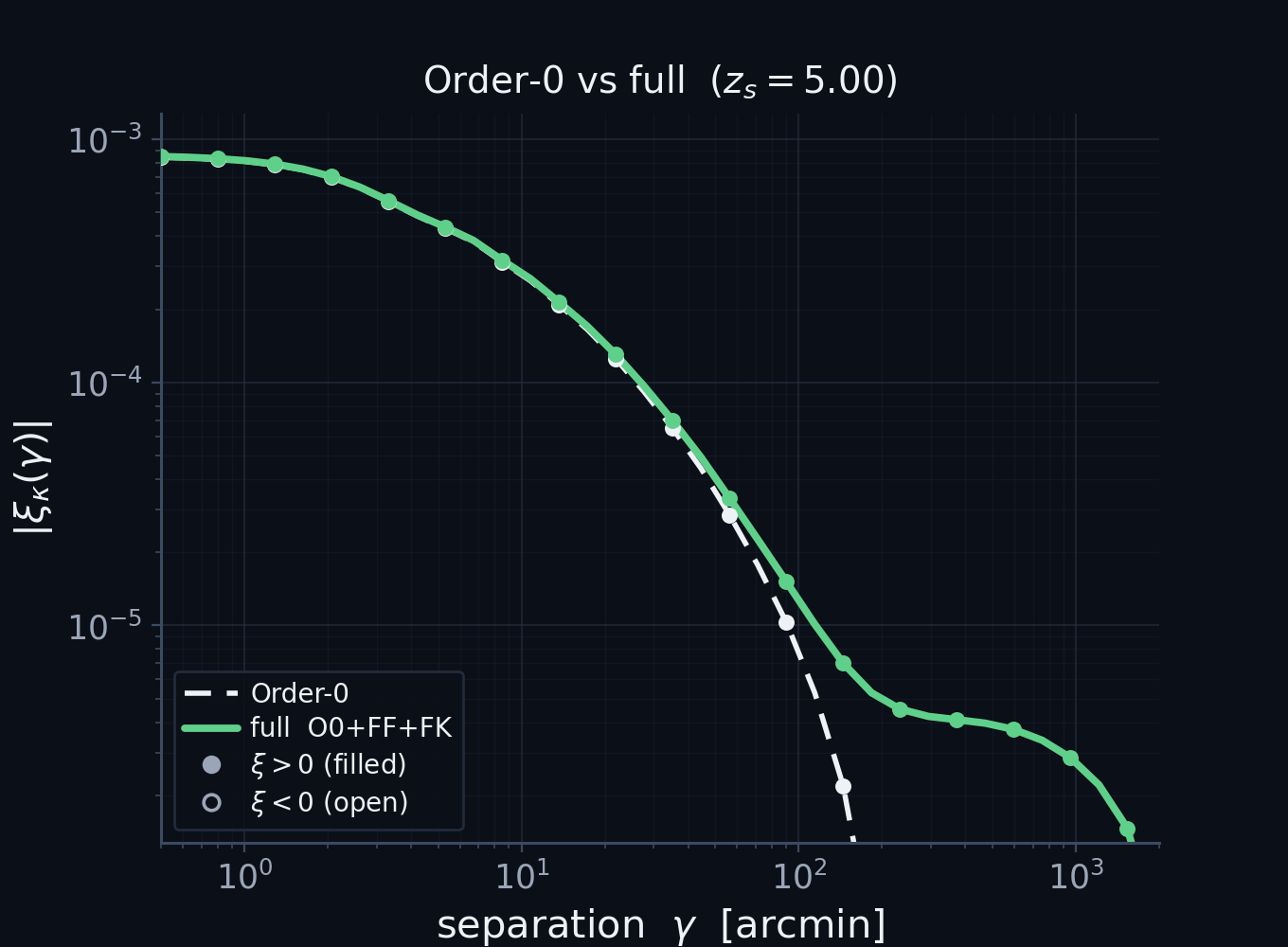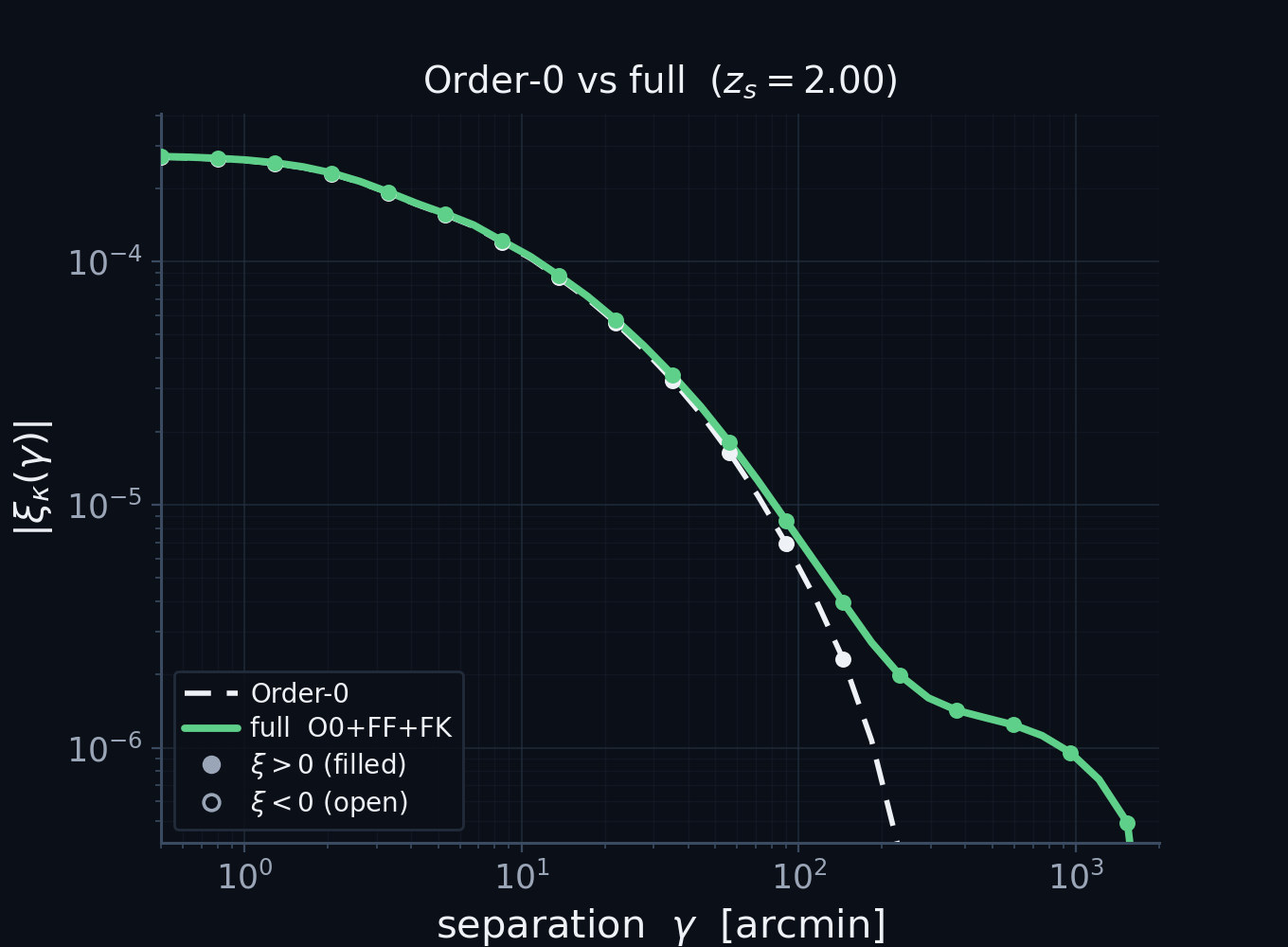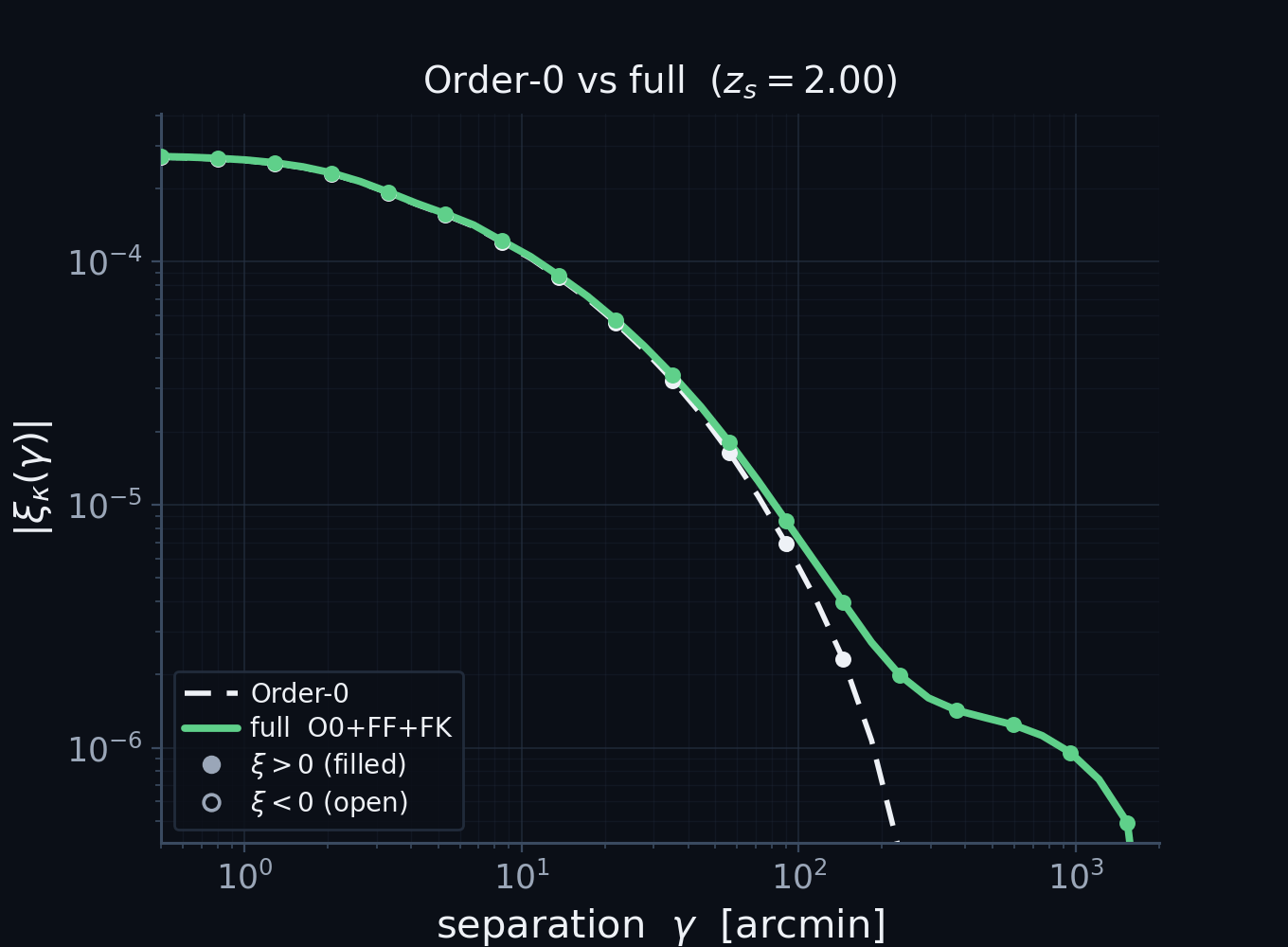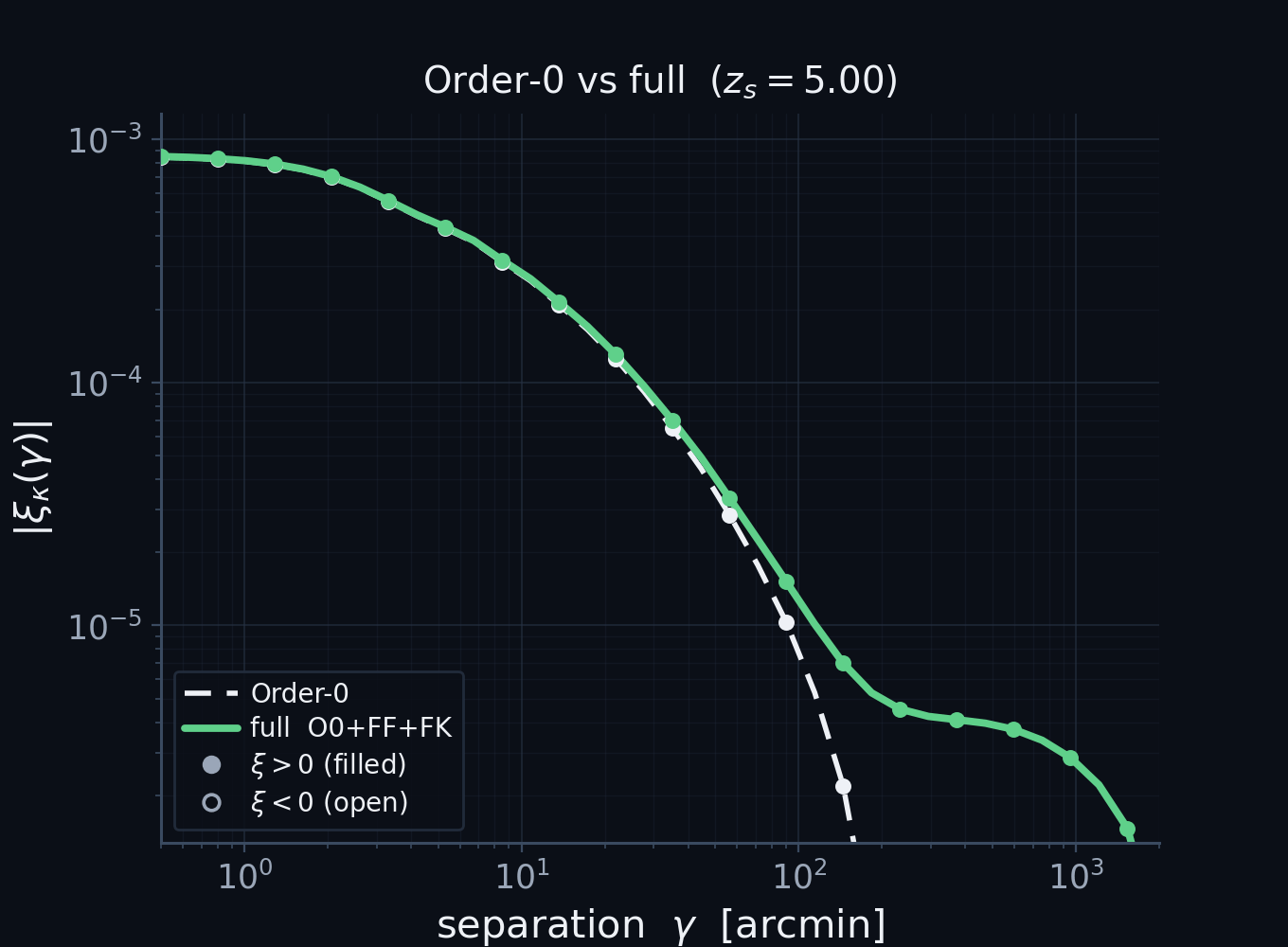
A unified view: the textbook kernel is Order-0
Order-0 (no vertices) reduces analytically to the standard non-Limber projection — not an analogy, the same integral.
Matches an independent PyCCL computation at the few-percent level (\(0.5'\!-\!2000'\), all four 2-point functions).
\(z_s=5\); \(|\xi|\) on log axes, filled \(=\xi>0\)/open \(=\xi<0\). The ratio departs only at the sign-flip zero-crossing.
[First money plot. The validation that licenses everything else.] Take the expansion at order zero, no vertices. Analytically it reduces, after the change of radial variable to comoving distance, to exactly the conventional weak-lensing projection. Not an analogy, the same integral: the textbook kernel is literally the zeroth-order diagram. And it is right. Here is our order-zero prediction against an independent calculation from PyCCL, run with its non-Limber integrator. Plotted as the absolute correlation on log axes, with filled markers where it is positive and open where it turns negative, so you can see it cross zero near a few hundred arcminutes. Across all four two-point functions, from half an arcminute to two thousand, the two pipelines agree at the few-percent level, departing only right at the sign change. Because order zero already matches an independent code, every departure I show next is genuine physics, not a bug.
Part 3 · Insight B
Mixing Hierarchy & A Selection Rule
Mixing Hierarchy
A driving-field \(n\)-cumulant can feed different-order observables — but at a definite cost: each step its index runs ahead of the observable's adds one \(F\)-vertex, i.e. one higher order.
A Selection Rule
At a fixed order an \(n\)-point observable couples to exactly one cumulant: leading is \(\kappa^{(n)}\); the first correction reaches \(\kappa^{(n+1)}\) through one \(F\)-vertex. Higher cumulants are forbidden until higher order.
For \(\xi\) this singles out the bispectrum \(\kappa^{(3)}\) — structure from perturbative expansion, not a truncation by hand.
[The structural payoff. Walk the figure left-to-right.] The second insight is about which statistics can talk to which, and it has two parts. First, a mixing hierarchy: a driving-field n-cumulant can feed different-order observables, but at a definite cost. The further its index runs ahead of the observable's, the more nonlinear-propagation F-vertices you need, and so the higher the order. The figure reads that off: the three-cumulant reaches the three-point function at order one, through a single K vertex; it reaches the two-point function only at order two, an F plus a K; the four-cumulant reaches the three-point at order two and the two-point only at order three. Second, the flip side is a selection rule: at any fixed order an n-point observable couples to exactly one cumulant, leading with the n-th and reaching the n-plus-first through one F; higher cumulants are simply forbidden, there is no diagram. For the two-point function that singles out the three-cumulant, the bispectrum, as the unique leading non-Gaussian contributor. It is structure from perturbative expansion, not a truncation by hand, and it tells you exactly which matter statistic can contaminate which lensing measurement.
Part 3 · Insight C
A squeezed 3-cumulant leaks into the 2PCF at large scales
Order-0, FF, FK and the full sum O0+FF+FK (\(z_s=5\)).
FK \(>\) FF : the bispectrum term exceeds the nonlinear-propagation (FF) term by ~2× at arcmin scales (several× by tens of arcmin).
On a \(z_s=5\) plane the full sum departs from Order-0, FK overtaking beyond ~120' (~2°) (for our tree-level bispectrum model) .
Separable: FK lives only in \(\xi_\kappa,\xi_+\).
Harmonic-space image: the FK leak is excess power at low \(\ell\) in \(C_\ell^{\kappa\kappa}\).
[The headline. Left: the order-2 terms. Right: where it lives.] Here is the punchline. The FK term, the matter bispectrum fed through one propagation gate, is not a small wiggle. In the convergence and the parity-even shear it exceeds the FF nonlinear-propagation term by about a factor of two at arcminute scales, growing to several times by tens of arcminutes, and on a redshift-five source plane it overtakes the falling linear signal beyond about two degrees, for our tree-level bispectrum model. And why is this good news? Because of the spine of the talk: the two curvature channels carry different spin on the sky. FK appears only in the convergence and the parity-even shear, the modulus channels; it falls to the floor in the shear difference and the convergence-shear cross, by spin geometry. So FF and FK sit in different combinations of the shear data vector: separable, not degenerate. The next two slides: how it scales with redshift, and a direct-simulation check.
Part 3 · Insight C
The leakage grows with source redshift
Full (O0+FF+FK) vs Order-0 , swept over source planes \(z_s=0.5\to5\).
The turning point — where FK overtakes Order-0 — marches to smaller scales as \(z_s\) grows: from \(\sim\)280' at \(z_s=0.5\) to \(\sim\)120' (\(\sim\)2°) at \(z_s=5\).
Most consequential for deep, high-redshift samples (Euclid/Roman tails, CMB lensing).
[Redshift trend; let the sweep run.] How general is this? This is the same calculation swept across source redshift, reusing the machinery: the full prediction, order-zero plus FF plus FK, against order-zero alone, as the source plane moves from redshift one-half out to five. The animation starts on the redshift-five plane, the components you just saw; then it drops the FF and FK lines and sweeps the source redshift. As the source redshift grows, the turning point where the bispectrum term overtakes order-zero marches to smaller scales, from about two hundred eighty arcminutes at redshift one-half down to about two degrees at redshift five; the FK leakage itself climbs by roughly a factor of twelve from redshift one to five. So this is least important for shallow surveys and most consequential exactly where Stage-IV is heading: the deep, high-redshift tails of Euclid and Roman, and ultimately CMB lensing.
Part 3 · Insight C · validation
Checked against direct simulation
A brute-force Monte-Carlo of the full non-Gaussian Sachs system (the \(K\) vertex is active) reproduces the SFT full prediction O0+FF+FK .
\(|\xi|\) on log axes (filled \(=\xi>0\), open \(=\xi<0\) ): the direct simulation tracks the diagram sum, sign change and all. The expansion is not just internally consistent — it matches the numbers you get by brute force.
[Apple-to-apple validation with the non-local vertex on.] Finally, a direct check. We run a brute-force Monte-Carlo of the full nonlinear Sachs system with a non-Gaussian, skewed driving field, so the non-local K vertex is genuinely active. The total two-point function it measures is compared, apple to apple, against the SFT full prediction, order-zero plus FF plus FK. Plotted as the absolute correlation on log axes, with filled markers where it is positive and open markers where it turns negative, the direct simulation tracks the diagram sum, including through the sign change at large angles. So the expansion is not just internally consistent; it reproduces the numbers you get by brute force, including the non-Gaussian FK piece. The decomposition into the separate Gaussian and FK checks is in the backup.
Summary
Not a substitute for conventional methods.
But a necessary reorganization & paradigm improvement .
Bad news Large-scale two-point lensing is contaminated by non-Gaussian structure — small-scale power leaks to large angles along the squeezed \(\kappa^{(3)}\).
Good news You can probe cosmic non-Gaussianity with the two-point function itself.
The same machinery describes any null congruence in a random spacetime — e.g. lensing of the stochastic GW background.
[Lift it from "useful" to "necessary," then open the door.] The one-line summary: this is not a substitute for conventional methods, it is a necessary reorganization and a paradigm improvement. The bad news first: a two-point lensing analysis is contaminated at large angles by non-Gaussian structure, because small-scale power leaks up to large scales through the squeezed three-cumulant, exactly where you would not look for it, and lumping it into a post-Born or FF model biases what you infer. The good news, the flip side: precisely because an n-point observable leads with the n-th cumulant, you can probe cosmic non-Gaussianity with the humble two-point function. And because the construction starts from the Sachs system rather than a lensing-specific projection, the same machinery describes any null congruence in a random spacetime, including lensing of the stochastic gravitational-wave background. It is a field theory for the propagation of light, of which weak lensing is the first application.
Take-aways
Three things to remember
The textbook lensing kernel is the zeroth-order diagram of one systematic expansion.
A selection rule ties the observable hierarchy to the driving-field cumulant hierarchy.
Small-scale non-Gaussianity (FK ) contaminates large-angle 2-pt lensing — but is separable by spin, and grows with \(z_s\).
Thank you — questions welcome. zheng.zhang@manchester.ac.uk
with the support of
[Recap and invite questions.] To summarize. First: the textbook lensing kernel is not a separate model; it is the zeroth-order diagram of one systematic field-theory expansion, matching an independent code at the few-percent level. Second: a selection rule, from diagram topology, ties the order of a lensing observable to the driving-field cumulant it can reach. Third: through that channel, small-scale non-Gaussianity contaminates large-angle two-point lensing, comparable to and beyond the linear signal, growing with source redshift, but separable because the two curvature channels carry different spin. Thanks to my collaborators and to the sft-wick, canoes and gevolution codes. Happy to take questions.
Backup
Backup slides
Non-Limber propagators · 3-pt diagrams · squeezed bispectrum · input 3-cumulant validation · coordinate maps
(press ↓ to browse)
Non-Limber propagators
Response propagator \(R\)
Correlation propagator \(C\) slices
Three-point diagrams (Order-1)
One \(F\) or one \(K\) vertex feeds the convergence 3-point function.
Squeezed driving-field bispectrum
Equal-shell 3rd cumulant on the squeezed configuration; small-scale modes set the sign below ~40'.
Input 3-cumulant validation (vs fastnc )
Cosmic-shear 3PCF amplitude on isosceles triangles (\(\gamma=50'\), opening angle \(\varphi\)): our SFT \(\zeta_D\) (cyan) vs the independent tree-level code fastnc (Sugiyama+2024, amber). Agreement within a factor of 2 across triangle shapes validates the input driving-field 3-cumulant.
Light-cone coordinate maps
\(\chi(\lambda)\) and \(z(\lambda)\) along the past light cone.